-
2.SpringBatch 코드 설명 및 아키텍처 알아보기Spring/Spring Batch 2024. 10. 20. 22:27
앞선 과정에서 SpringBatch 프로젝트를 구성 및 실행을 해보았습니다.
이번에는 Job, step에 대해 알아보고 SpringBatch 아키텍처에 대해 학습해보도록 하겠습니다.
1.Spring Batch 아키텍처
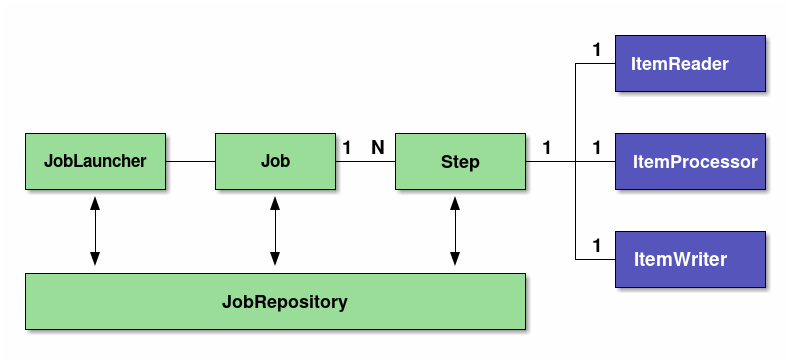
- Job
- Spring Batch에서 일괄 적용을 위한 일련의 프로세스를 요약하는 단일 실행 단위가 된다.
- Step
- Job을 구성하는 처리단위이다.
- 하나의 Job에는 여러 Step이 들어갈 수 있다. 1: N 구조로 되어있다.
- 하나의 Job에 여러 Step을 재사용, 병렬화, 조건분기 등을 수행할 수 있다.
- Step은 tasklet 모델 / chunk 모델의 구현체가 탑재되어 실행된다.
- JobLauncher
- Job을 수행하기 위한 인터페이스이다.
- JobLauncher는 사용자에 의해서 직접 수행된다.
- 자바 커맨드를 통해서 CommandLineJobRunner 를 실행하여 단순하게 배치 프로세스가 수행될 수 있다.
- ItemReader
- 청크단위 모델에서 사용하며, 소스 데이터를 읽어 들이는 역할을 수행한다.
- ItemProcessor
- 읽어들인 청크 데이터를 처리한다.
- 데이터 변환을 수행하거나, 데이터를 정제하는 등의 역할을 담당한다.
- 옵션으로 필요없다면 사용하지 않아도 된다.
- ItemWriter
- 청크 데이터를 읽어들였거나, 처리된 데이터를 실제 쓰기작업을 담당한다.
- 데이터베이스로 저장하거나, 수정하는 역할을 할 수 있고, 파일로 처리결과를 출력할 수도 있다.
- Tasklet
- 단순하고 유연하게 배치 처리를 수행하는 태스크를 수행한다.
- JobRepository
- Job과 Step의 상태를 관리하는 시스템이다.
- 스프링배치에서 사용하는 테이블 스키마를 기반으로 상태정보를 저장하고 관리한다.
2. 스프링배치 흐름
앞세 살펴봤던 아키텍처에서 배치의 흐름이 어떻게 흘러가는지 알아보자.

처리흐름 관점
- JobScheduler 가 배치를 트리거링 하면 -> JobLauncher 를 실행
- JobLauncher 는 Job을 실행 -> JobExecution 을 수행하고, Execution Context 정보를 이용한다.
- Job은 ->Step을 실행한다. 이때 StepExecution을 수행하고, Execution Context 정보가 전달되어 수행된다.
- Step은 Tasklet과 Chunk모델을 가지고 있으며 위 그림에서는 Chunk 모델로 수행되게 된다.
- Chunk 모델은 ItemReader를 통해서 소스 데이터를 읽어 들인다.
- ItemProcessor를 통해서 읽어들인 청크단위 데이터를 처리한다. 처리는 데이터를 변환하거나 가공하는 역할을 하게 된다.
- ItemWriter는 처리된 청크 데이터를 쓰기작업한다. 다양한 Writer를 통해 데이터베이스에 저장하거나, 파일로 쓰는 역할을 하게 된다.
Spring Batch에서 Chunk란?
Chunk는 Spring Batch에서 대량 데이터를 처리할 때 효율적인 방법 중 하나로, 데이터를 읽기(Read), 처리(Process), **쓰기(Write)**의 단위로 나누어 실행하는 방식입니다. 즉, 전체 데이터를 한 번에 처리하지 않고, 일정한 크기로 나누어 처리하는 것이 특징입니다.
• Chunk 단위: 한 번에 처리할 데이터의 크기를 정의합니다. 예를 들어, chunkSize=10으로 설정하면 10개의 데이터씩 읽고 처리한 후 저장합니다.
• Chunk 기반 처리 흐름: 데이터를 읽고 → 처리하고 → 일정량이 모이면 → 한 번에 기록(Write)하는 방식입니다.
Tasklet과 Chunk의 차이
• Tasklet: 하나의 큰 작업을 단순하게 정의한 단위입니다. 예를 들어, 파일 읽기, 데이터 처리, DB에 쓰기 등의 작업을 순차적으로 한 번에 처리합니다.
• Chunk: Tasklet과 달리 데이터를 일정한 크기로 나누어 처리할 수 있으며, 대용량 데이터를 처리하는 데 적합합니다. 처리 중 에러가 발생해도, 특정 Chunk만 재처리할 수 있어 유연하고 효율적입니다.
왜 Chunk로 작업을 구성해야 하는가?
1. 효율적인 메모리 관리: 대용량 데이터를 한 번에 처리하면 메모리 부족 문제가 발생할 수 있습니다. Chunk는 데이터를 나누어 처리하기 때문에 메모리 사용량을 줄일 수 있습니다.
2. 재처리 용이: 처리 중간에 오류가 발생하면, 전체 작업을 다시 수행하는 대신 해당 Chunk만 다시 처리할 수 있어 효율적입니다.
3. 성능 최적화: Chunk는 일정 단위로 데이터를 일괄 저장하므로, I/O 작업 횟수를 줄여 성능을 향상시킬 수 있습니다. 예를 들어, 매번 데이터베이스에 쓰는 대신 Chunk 단위로 데이터를 일괄 처리합니다.
4. 대용량 데이터 처리: 대규모 배치 작업에서 전체 데이터를 한 번에 처리하기 어려운 경우, Chunk는 대량 데이터를 나누어 처리할 수 있어 더 안정적입니다.
이러한 이유로, Tasklet보다 Chunk 기반 작업 구성이 대량 데이터 처리나 복잡한 배치 처리에서 더 유리합니다.
결론: Tasklet은 단순한 작업 처리에 적합하지만, 대량 데이터 처리에서는 메모리 사용과 에러 처리의 효율성을 위해 Chunk 기반 처리가 더 권장됩니다.
3.Tasklet 구현체 생성하기
- GreetingTasklet.java 파일을 생성하고 다음과 같이 작성한다.
import lombok.extern.slf4j.Slf4j; @Slf4j public class GreetingTask implements Tasklet, InitializingBean { @Override public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception { log.info("------------------ Task Execute -----------------"); log.info("GreetingTask: {}, {}", contribution, chunkContext); return RepeatStatus.FINISHED; } @Override public void afterPropertiesSet() throws Exception { log.info("----------------- After Properites Sets() --------------"); } }- 보는바와 같이 Tasklet과 InitializeBean 인터페이스를 구현한다.
- Tasklet은 execute 메소드를 구현해야한다.
- InitializeBean은 afterPropertiesSet 메소드를 구현해야한다.
- execute:
- execute메소드는 StepContributioin 과 ChunkContext 를 파라미터로 받는다.
- 최종적으로 RepeatStatus 를 반환하며 이 값은 다음과 같다.
- FINISHED: 태스크릿이 종료되었음을 나타낸다.
- CONTINUABLE: 계속해서 태스크를 수행하도록한다.
- continueIf(condition): 조건에 따라 종료할지 지속할지 결정하는 메소드에 따라 종료/지속을 결정한다.
- afterPropertiesSet:
- 태스크를 수해할때 프로퍼티를 설정하고 난 뒤에 수행되는 메소드이다.
- 사실상 없어도 된다.
4. Job, Step 을 생성하고 빈에 등록
package com.schooldevops.springbatch.batchsample.config; import org.springframework.batch.core.Job; import org.springframework.batch.core.Step; import org.springframework.batch.core.job.builder.JobBuilder; import org.springframework.batch.core.launch.support.RunIdIncrementer; import org.springframework.batch.core.repository.JobRepository; import org.springframework.batch.core.step.builder.StepBuilder; import org.springframework.batch.core.step.tasklet.Tasklet; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.transaction.PlatformTransactionManager; import com.schooldevops.springbatch.batchsample.GreetingTask; import lombok.RequiredArgsConstructor; import lombok.extern.slf4j.Slf4j; @Slf4j @Configuration @RequiredArgsConstructor public class BasicTaskJobConfiguration { private final PlatformTransactionManager transactionManager; @Bean public Tasklet greetingTasklet() { return new GreetingTask(); } @Bean public Step step(JobRepository jobRepository, PlatformTransactionManager transactionManager) { log.info("------------------ Init myStep -----------------"); return new StepBuilder("myStep", jobRepository).tasklet(greetingTasklet(), transactionManager) .build(); } @Bean public Job myJob(Step step, JobRepository jobRepository) { log.info("------------------ Init myJob -----------------"); return new JobBuilder("myJob", jobRepository).incrementer(new RunIdIncrementer()) .start(step) .build(); } }- Tasklet, step, Job을 구현하고 Bean으로 등록한다.
- step 구성 시 PlatformTransactionManager와 jopRepository를 파라미터로 받는다.
- Job 구성 시 시작 점 구성을 위해 step을 파라미터로 받는다.
5. 실행결과
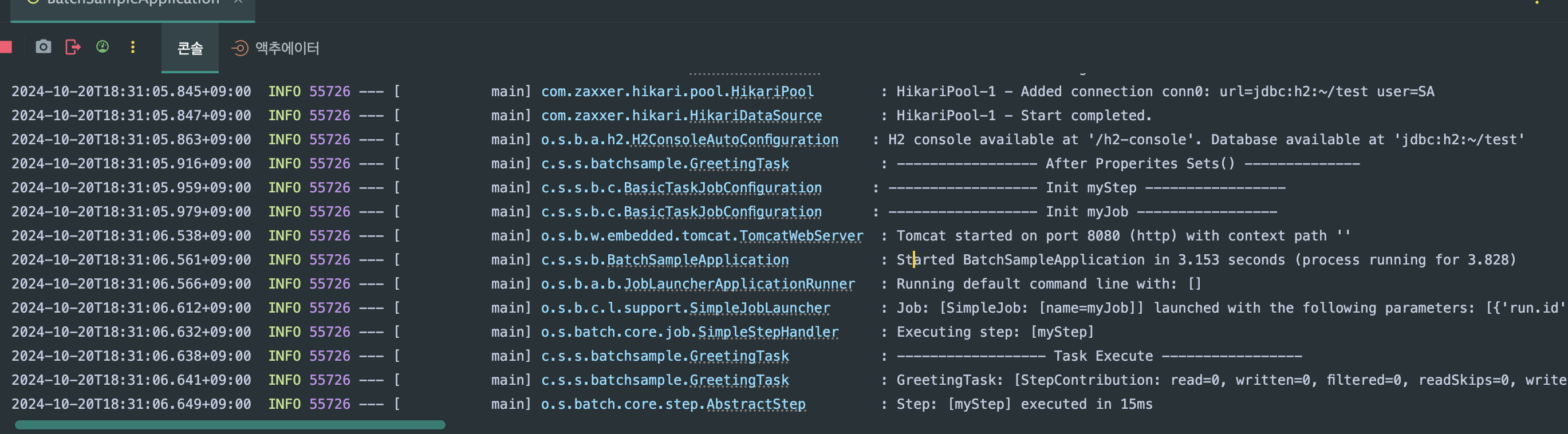
로그를 보면 Spring Batch에서 myStep의 로그가 myJob의 로그보다 먼저 출력되었다. 그이유는 무엇일까?
1. Bean 초기화 순서
Spring에서 빈은 의존성 주입과 초기화 순서에 따라 설정됩니다. myJob은 myStep을 의존하므로, myStep이 먼저 생성되고 초기화된 후에 myJob이 초기화됩니다.
이 과정에서 @Bean으로 정의된 step() 메서드가 먼저 호출되어 myStep을 초기화하고, 그 후 myJob() 메서드가 호출되어 myJob을 초기화합니다.
2. 코드 분석
• myJob 빈을 생성할 때 step이 필요하므로, Spring은 먼저 step 빈을 초기화하고, 해당 단계에서 로그가 찍힙니다.
• step() 메서드에서 greetingTasklet()과 transactionManager가 호출되면서 myStep이 초기화되고, 로그가 출력됩니다.
• 그 이후 myJob이 생성되며 myJob 로그가 출력됩니다.
결론
myJob은 step을 의존하기 때문에, Spring이 의존 관계에 맞춰 step 빈을 먼저 초기화하면서 해당 로그가 먼저 찍힌다.
'Spring > Spring Batch' 카테고리의 다른 글
7. MyBatisPagingItemReader로 DB내용을 읽고, MyBatisItemWriter로 DB에 쓰기 (2) 2024.11.18 5. JdbcPagingItemReader로 DB내용을 읽고, JdbcBatchItemWriter로 DB에 쓰기 (0) 2024.11.05 4. FlatFileItemReader로 단순 파일 읽고, FlatFileItemWriter로 파일에 쓰기 (0) 2024.11.04 3.SpringBatch ChunkModel과 TaskletModel (1) 2024.10.21 1.SpringBatch 빠르게 시작하기 (3) 2024.10.20 - Job